LaBB-CAT
Language, Brain & Behaviour Corpus Analysis Tool
(Formerly known as ONZE Miner)
|
LaBB-CAT is a browser-based linguistics research tool that stores audio or video recordings, text transcripts, and other annotations. Annotations of various types can be automatically generated or manually added. The transcripts and annotations can be searched for particular text or regular expressions. The search results, or entire transcripts, can be viewed or saved in a variety of formats, and the related parts of the recordings can be played or opened in acoustic analysis software, all directly through the web-browser. |
What does it do?
Storage of Media and Transcripts
LaBB-CAT is essentially a repository for time-aligned transcripts of audio/video recordings. Time-aligned transcripts can produced using Transcriber, Praat, or ELAN (which can be used to create a document lining up the transcript text with the corresponding location in the audio/video recording). The transcript is then uploaded to LaBB-CAT, which allows additional information about the speakers and the transcripts to be stored.

Elicitation Tasks
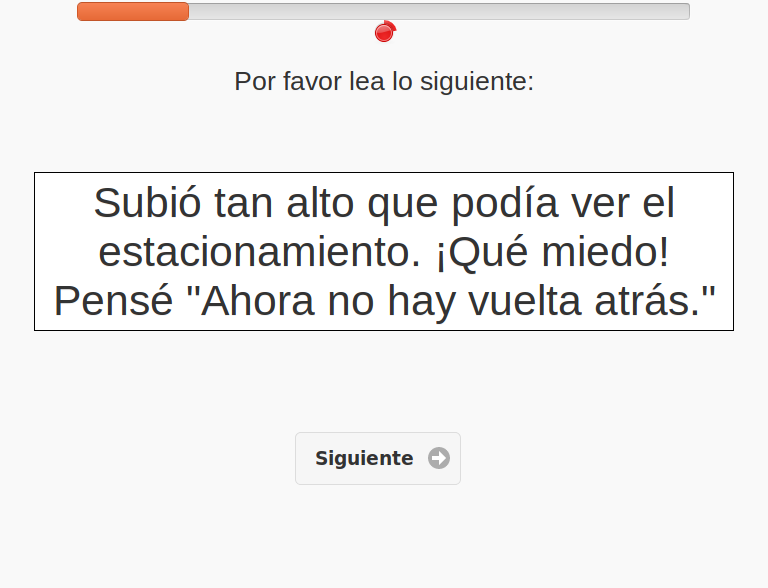
You can also define elicitation tasks that include prompts for participants to read and questions for them to answer.
When a participant does the task (using their browser or a mobile device) their speech is recorded and automatically uploaded directly into LaBB-CAT:
Automatic Annotation
Combining the signal data, the raw orthographic transcriptions, and some third-party data and tools, the transcripts can be automatically annotated, for example:
Lexical tagging

With the help of data from CELEX, words can be automatically annotated with further data:
- phonology
- syllabification
- morphology
- part of speech
- frequency
Other lexicons can also be integrated, including the CMU Pronouncing Dictionary and the Unisyn Lexicon.
Forced Alignment
With the help of HTK or WebMAUS, transcripts aligned at the utterance level can be force-aligned to the word and segment level:

Statistical Layers
Word frequency data for the LaBB-CAT database itself can be computed and annotated directly on each word:

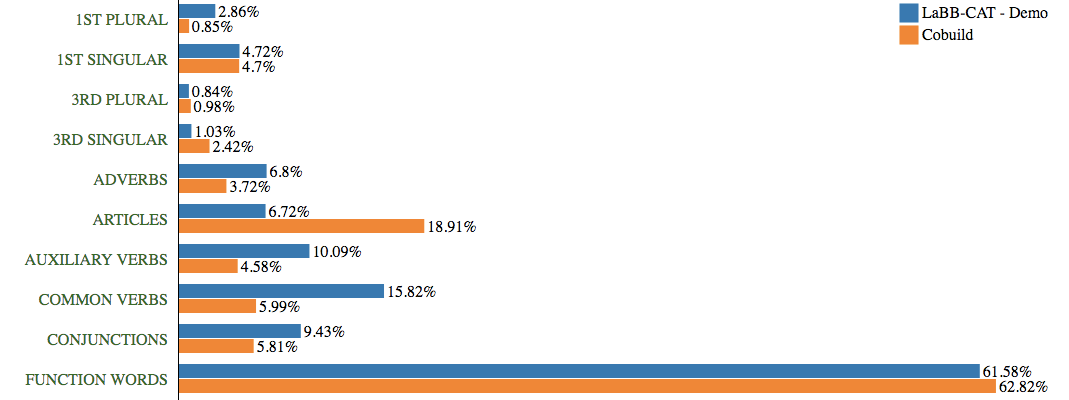
'Linguistic Inquiry and Word Count' (LIWC) can be used to compare the corpus to reference corpora:
Combining time alignment information and syllable count from CELEX, speech rate can be calculated over different domains:

Stanford Parser
With help from the Stanford Parser, editable syntactic trees can be generated for the transcripts:


Scripting
Scripts can be written in Python or Javascript to perform arbtrary computation and annotation tasks:

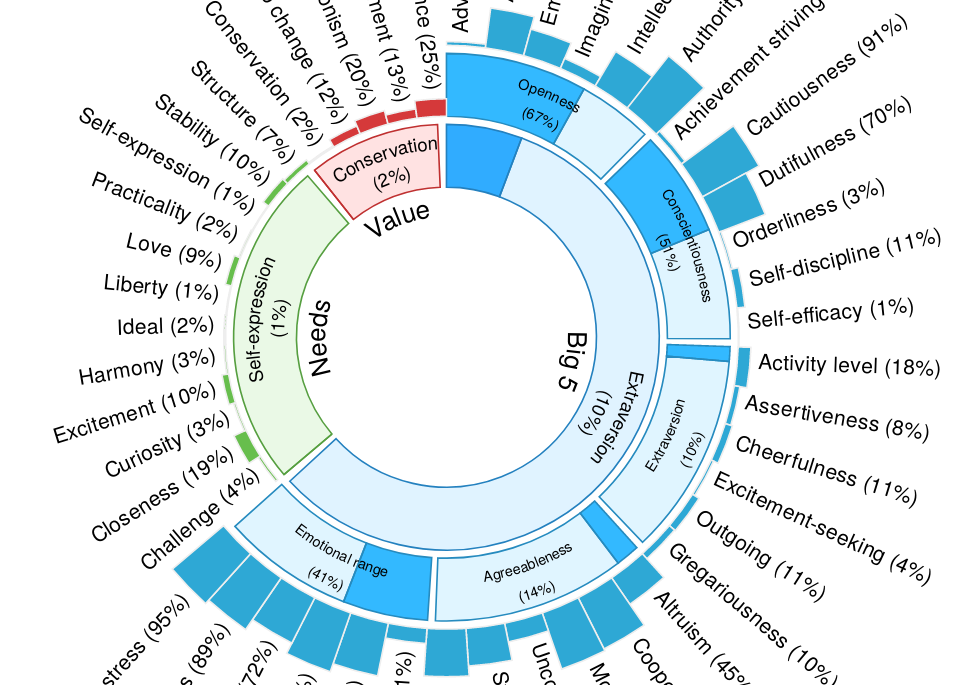
IBM Watson Personality Insights
LaBB-CAT can integrate with IBM Watson's Personality Insights web service, to perform personality analysis on transcripts:
Manual Annotation
Annotations can be manually added, e.g.
- Topic tagging
- Text tags against individual words
- Time points or intervals can be annotated using Praat:

Search
Once transcripts and annotations are in place, searches can be performed across transcripts which meet certain criteria (e.g. based on age/gender of the speaker, corpus the transcript belongs to, etc.):

When the speakers have been selected, their utterances can be searched for text or regular expressions, across different layers:

This returns a list of all of the utterances from the selected transcripts which match the query.

If desired, this list can be exported, together with relevant speaker and annotation information, directly to a CSV file, ready for further analysis in Excel or R:

Or audio samples can be extracted for analysis:

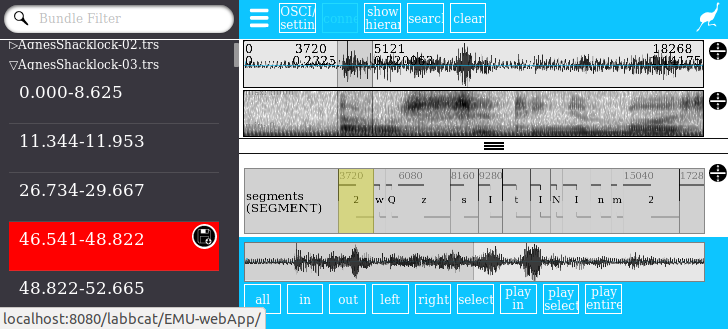
Or utterance annotations and alignments can be edited directly using the EMU-webApp:
If utterances have been force-aligned, targeted segments can be batch processed en-masse with Praat:
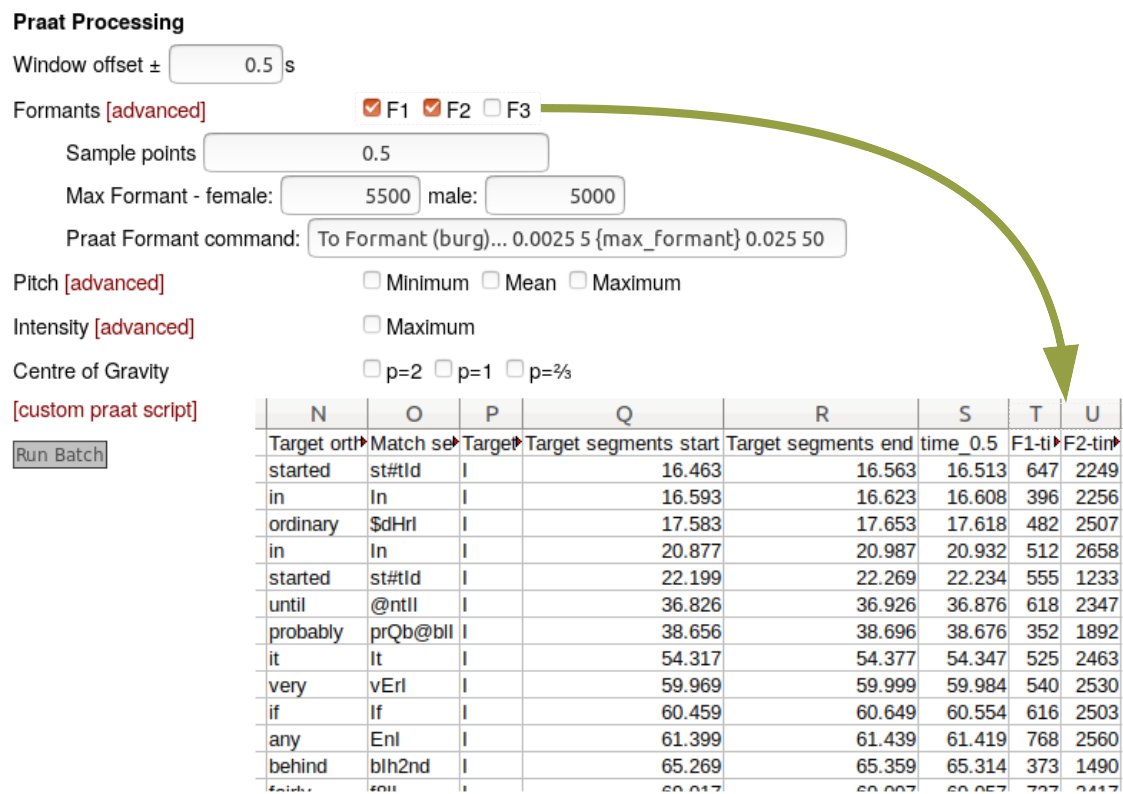
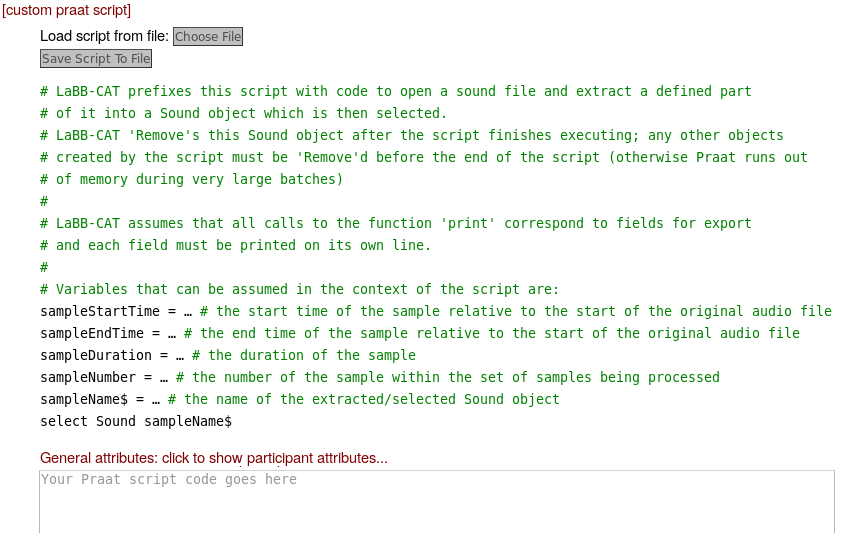
Batch Praat processing can include your own custom Praat scripts:
Alternatively, clicking on an utterance returned by the search produces the full transcript for the speaker involved, positioned with the relevant utterance at the top of the screen. Any part of the transcript can be clicked on, and the corresponding part of the media played:

Directly from the interactive transcript page, the media can be played, other annotation layers can be displayed, the audio for the line can be extracted, or opened in Praat with a corresponding TextGrid containing annotations. Annotations can be added, edited, or removed, and alignments adjusted.
What is Transcriber?
Transcriber is a free, 3rd-party software tool for creating and edited time-aligned transcripts - these are XML documents that line up transcript text with the corresponding part of the audio recording.
You can find out more about Transcriber here: http://trans.sourceforge.net
![]()
What is ELAN
ELAN (EUDICO Linguistic Annotator) is a 3rd-party tier-based media annotation tool developed by the Max Planck Institute for Psycholinguistics, which can be used both for orthographic transcription, and also extensive annotation on different tiers. It can be used to annotate multiple video files, and/or an audio file.
You can find out more about ELAN here: https://tla.mpi.nl/tools/tla-tools/elan/
What is Praat?
Praat is a free, 3rd-party software tool for acoustic analysis. Currently, through a web browser, LaBB-CAT is capable of interacting only with Praat.
Also, Praat can be used instead of Transcriber for creating transcripts.
You can find out more about Praat here: http://www.praat.org/
What is EMU-webApp?
The EMU-webApp is a 3rd-party online and offline web application for labeling, visualizing and correcting speech and derived speech data. It is component of the EMU-SDMS advanced speech database management and analysis system.
LaBB-CAT does not include all of EMU-SDMS, but it does use the EMU-webApp to label annotations and correct alignments in LaBB-CAT.
What do I need for LaBB-CAT to work for me?
A server computer with
- a web server that supports java server pages and java servlets (we have used LaBB-CAT with Microsoft IIS, and with Apache)
- Java
- MySQL, which is open-source software
- Apache Tomcat, which is open-source software
- LaBB-CAT
Because LaBB-CAT is written in Java, your server can run under Windows, Linux, or Macintosh OS X.
Any client computers that you wish to use to search the LaBB-CAT must have:
- network access to the server
- a web browser
They can run under Windows, Linux, or Macintosh OS X
To interact with Praat, they must also have Praat installed.
You may also install Transcriber to create transcripts with, or you can do transcription with Praat or ELAN.
Alternatively LaBB-CAT can be used as a 'standalone' system - i.e. the 'server computer' and the 'client computer' can be the same, in which case no network access is required.
How do I get LaBB-CAT?
LaBB-CAT can be downloaded from here: https://sourceforge.net/projects/labbcat/files/install/.
There you will find two possible files for downloading:
- install-labbcat-personal_yyyymmdd.jar - use this if you want to install LaBB-CAT on your Windows or MacIntosh personal computer, for private use, or
- labbcat-server_yyyymmdd.zip - use this if you want to install LaBB-CAT on a server shared between various users.
If you do install LaBB-CAT, please drop us a line, and let us know what you are using it for, and whether the installation goes smoothly.
You may also be interested in perusing these tutorial Videos, which demonstrate various features of LaBB-CAT.
There is also an article outlining the architecture and construction of LaBB-CAT, and another describing more recent changes.
How much does LaBB-CAT Cost?
LaBB-CAT is Open Source software, published with GNU's General Public License.
You can install and use it free of charge, and you can change and redistribute it freely, as long as your changes are also released as Open Source software. For more information, visit GNU: http://www.gnu.org/licenses
Who wrote LaBB-CAT?
The system was designed and written by Robert Fromont and Jen Hay for the ONZE (Origins of New Zealand English) Project, at the New Zealand Institute of Language, Brain and Behaviour.
Why?
The ONZE Project has a large (around 1000 hours) corpus which contains recordings of people born in New Zealand from the 1850s to the 1980s. The ONZE Project was originally conceived as a project that traced the development of the New Zealand accent. Three different types of phonetic/phonological analyses have been carried out: auditory perceptual analyses, auditory quantitative analyses and acoustic analyses.
Since 2003 we have been working on techniques for interacting more directly with the sound-files, via the orthographic transcript. That is, we wanted to introduce timestamping information into the transcript, so that a researcher could directly access any particular utterance of interest. After an initial exploration of appropriate tools, we settled on Transcriber software. NXpeds Footpedals were programmed for use with the software, so that transcribing into Transcriber proceeds very similarly to the traditional use of a transcription machine.
Because the format of the Transcriber files is XML, it can be relatively easily transformed into other formats. We therefore developed a simple java utility which would transform the Transcriber files into TextGrids for use with Praat acoustic analysis software.
In 2004 we began to develop software which allows these time-aligned transcripts to be stored on a central database, from where they can be easily viewed, filtered, and searched. The prototype of this software evolved into LaBB-CAT, and is proving highly successful, both for research, and for using the corpus in teaching. Part or all of the corresponding recordings can now be played-back or loaded into acoustic analysis software directly from the transcript.
This system has already radically increased the efficiency with which we can interact with the corpus. It raises exciting new possibilities for research projects that would have previously been extremely time-consuming.
Is there a demo?
Yes, there is a read-only demo of LaBB-CAT that you can access.
There are some online worksheets for self-directed exploration of LaBB-CAT's functionality which explain what to do.
If you just want to have a quick peek without working through exercises, the demo is here:
https://labbcat.canterbury.ac.nz/demo/
The username is: demo
The password is: demo
The LaBB-CAT Documentation site also includes some other options for worksheets and exercises.
And there are some demonstration videos here: